Quite a few back-end improvements to the vSkilled.com website this week.
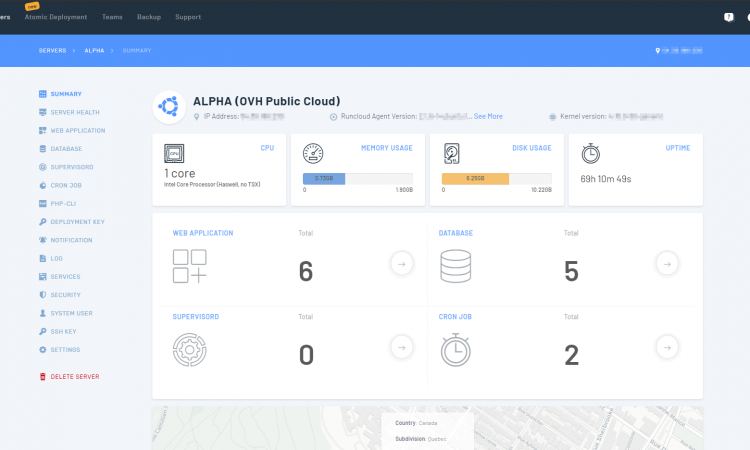
For starters the website was moved to a new server on OVH Public Cloud and it’s running RunCloud.io for management.
The website also runs in a dual-CDN configuration using both Cloudflare and BunnyCDN. Cloudflare acts as the primary web proxy while BunnyCDN serves up the media lightning quick.
vSkilled is now also using Redis Cache which has significantly improved the page loads as well as keeps the server load down.
Thank you to these companies for offering superior products and services.
This week NAS3 got a storage upgrade from 128GB SSD’s to 500GB SSDs. NAS3 is my SSD NAS which is used for hosting virtual machines.
NAS3 has been running with the 128GB SSD’s for many years now. In fact I paid more for the 128GB SSD than I did for the 500GB SSD. However that was exactly my reasoning for waiting so long to upgrade. NAS3 is not intended to be a performance beast since it’s limited to 1Gbps networking. It would literally be a waste to use high end SSDs in this machine.
Choosing an SSD is sometimes a difficult decision. You have to weigh the performance, cost, and endurance (quality) of the drive. Especially so in a NAS or RAID environment where SSD’s “total bytes written” or “TBW” endurance rating will become a factor.
I don’t like using a parity RAID with SSD’s because you will wear them out faster, but in this case I simply don’t care. I would rather have a little redundancy with the trade off of a faster wear rate. Considering the old 128GB SSD’s have been running in RAID5 for many years now as well, from my experience it’s not a big issue.
In RAID5 the disks give me 1.81 TB of usable SSD space. Compared to about 477GB before. So big upgrade in comparison.
This upgrade should last a few years at least. The next storage upgrade for the SSD side will be getting rid of the ancient Thecus N5550’s and replacing them with a Synology NAS. But that’s a future wish-list.
Hope you enjoyed reading. If so please drop a like or share.
Untangle SSL not working? A small hack here for those that might be struggling adding a third party signed certificate to their Untangle firewall.
Using self-signed certificates isn’t a problem. However when you try to add a trusted third party certificate to Untangle using the GUI it doesn’t work.
The GUI doesn’t seem to add the intermediate SSL certificate to the chain which causes the certificate to be broken and sometimes even a very broken Apache.
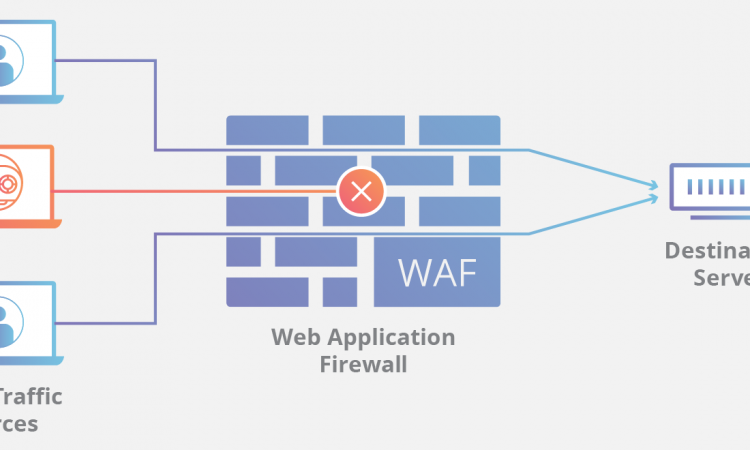
If you’re using Cloudflare for your website you might not realize the security protections that it can offer.
Using the free package you get access to setup up to five active firewall rules. On the Pro plan this goes up to 20 active firewall rules. The Pro plan also includes the Web Application Firewall (WAF) which will greatly improve security if you are not using any other type of WAF for your website.
What can we use these firewall rules for in a practical sense with WordPress?
Restrict access to wp-login.php
Restrict access to /wp-admin/
Block WordPress XML-RPC xmlrpc.php
On the free plan the easiest win is to implement 3 rules for the above. This will greatly reduce your outside attack surface.
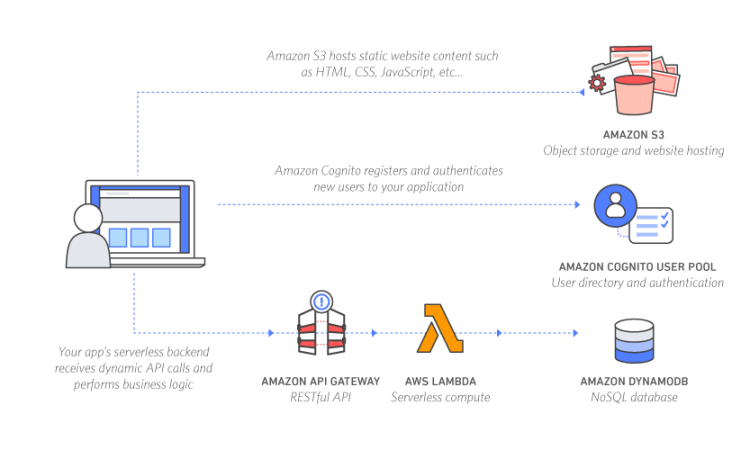
That is so far what my conclusion is at the time of this writing. I was looking again at the web tier for the vSkilled website. I want to ideally run the website serverless, but without ditching WordPress. Like many others I use WordPress as the back end CMS. It’s a powerful platform that can do almost anything you’d like within reason. I don’t really want to give that up just for the sake of a serverless architecture.
While that sounds like it should be possible – it’s really not ideal. There are services out there that help with this process, like Shifterand Hugo. But it’s not truly a serverless WordPress environment. How it works is by hosting a temporary WordPress website then when you’re done editing, converting the entire site to static content.
Today we will be talking about the VMware vCenter 6.7-U1 (Update 1) upgrade process. I recently had an opportunity to work with a enterprise customer to upgrade their VMware environment. In this post we will be going through the upgrade process and my thoughts. VMware 6.7 U1 is a major upgrade that includes the fully featured HTML5 client. For full details on what’s new please see: https://blogs.vmware.com/vsphere/2018/10/whats-new-in-vcenter-server-6-7-update-1.html
I will start by saying bravo to the VMware team for this release. For the first time I actually felt comfortable abandoning the good ol’ “fat client” (the legacy C# client). Many of VMware’s customers, in my experience, were intentionally lagging behind on older versions of vCenter to keep a cold death-grip on the fat client because they refused to be force-fed the flash client that we all know and despise. The HTML5 client is a worthy successor. It’s fast, it looks good, its organized better, and it even has a dark mode. It’s obvious they took feedback from the community, hired the right developers who understood their target audience, and put out a great product. The upgrade and migration process is also done very well.
After a few weeks of the VCSA and HTML5 client baked into the client environment it’s obvious that some things are still missing, like exporting events, from the HTML5 client but I would expect these to be eventually added. There also appears to be some lag to the recent tasks list in larger linked environments. I’ve also seen a few UI bugs with adding permissions and modifying sDRS configuration.
One issue I’ve seen on multiple VCSA’s so far is that the database “archive” (disk 13) will constantly fill up causing the VCSA to show up as degraded within the dashboard. You will be greeted with the error message “File system /storage/archive is low on storage space. Increase the size of disk /storage/archive.” There is very little documentation on this but apparently this is expected behavior despite the warnings and rational I don’t quite understand yet. This didn’t stop me from increasing the disk size (KB2126276) slightly. [2019-04-12: This issue is now fixed by VMware.]