On October 17, 2018 VMware announced that vSphere 6.7 Update 1 is now available. The new HTML5 client is now ‘Fully Featured’ which means that you can use the HTML5 client for all administration and configuration of vSphere; including Auto Deploy, Host Profiles, VMware vSphere Update Manager (VUM), vCenter High Availability (VCHA), network topology diagrams, overview performance charts, and more.
I am personally excited to see the HTML5 client become the primary client as I much prefer using it over the flash client. One of the more interesting features included in this release is the vCenter External to Embedded Convergence tool. Since embedded PSC is the recommended deployment model for vCenter Server this tool allows you to migrate to an embedded PSC without having to nuke-and-pave your entire vCenter installation.
The Content Library also got some much needed love from the VMware development team as it now supports two more new file formats; allowing templates and OVA files. This makes the Content Library much more functional. The lack of VM templates was a major caveat of the Content Library to the point of making it practically useless for some VMware customers. So this change is a welcome one to say the least.
New Features
- vCenter High Availability (VCHA)
- We redesigned VCHA workflows to combine the Basic and Advanced configuration workflows. This streamlines the user experience and eliminates the need for manual intervention of some deployments.
- Search Experience
- We revamped the search experience. In this version of the vSphere Client, you can now search for objects with a string and filter the search results based on Tags/Custom attributes. You can also filter the object lists in the search even further. For instance, you can filter on the power state of the VMs etc., You can save your searches and revisit them later.
- Performance Charts
- You can pop the performance charts into a separate tab and zoom in on a specific time in the chart. We also added overview performance charts for datacenters and clusters.
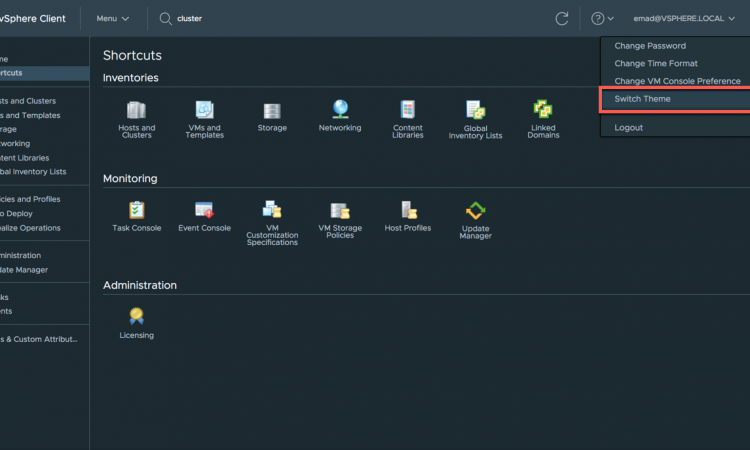
- Dark Theme
- Dark theme has been one of the most requested features for the vSphere Client so we’re introducing a Dark mode setting. Support for the Dark theme is available for all core vSphere Client functionality and implementation for vSphere Client plugins is in progress.
- Alarm Definitions
- We greatly simplified the way you define new alarms, particularly in how you create rules for trigger conditions.